Estoy fervientemente convencido que enseñar conceptos de POO sin ayuda de UML es elegir el camino más empinado para el novicio. Cuando de abstracciones se trata, el cerebro trabaja mejor jugando con "imágenes", creando simples representaciones de lo que llamamos objetos y sus relaciones (tema que trataremos en otro artículo).
Bueno, no perdamos más tiempo y solucionemos esta carencia en 6 pasos concretos ;-)
Introducción: Representación de una clase
Una clase se representa con un "rectángulo" dividido en 3 zonas horizontales:
- La primer zona se utiliza para colocar el nombre de la clase. Por convención los nombres de las clases inician con la primera letra en mayúsculas, y todas en singular (Persona, Cliente, Vendedor, Perro, Fruta, etc)
- La segunda zona se utiliza para colocar la lista de atributos. Cada atributo iniciará con un símbolo que representará la "visibilidad" del mismo, que podrá ser "público" (+), "privado" (-) o "reservado" (#).
- La tercer zona se utiliza para colocar los métodos de la clase. Cada método, igual que sucede con los atributos, deberá tener los mismos símbolos de "visibilidad" que se aplican con los atributos.
 En este ejemplo podemos observar además que para cada atributo o método deberemos definir cual será el tipo de valor que manejará (String, Date, Integer, etc), no importando verdaderamente si nuestro lenguaje lo soporta en un 100%.
En este ejemplo podemos observar además que para cada atributo o método deberemos definir cual será el tipo de valor que manejará (String, Date, Integer, etc), no importando verdaderamente si nuestro lenguaje lo soporta en un 100%.No hay que olvidar que UML es un lenguaje de modelado que permite comprender los diseños sin tener que llegar a conocer el código, y la traducción no está atada a ningún lenguaje de programación. Si el lenguaje es OO, se puede traducir, y tal vez, algunos detalles menores queden por el camino, pero que no debería afectar al concepto general de lo que se quiere transmitir.
Por ejemplo, PHP es un lenguaje de "tipado dinámico" (o lo opuesto a decir "tipado fuerte") donde según la asignación de valores (o su contexto de uso) define el tipo de la variable. Para el caso de la traducción del UML, cada vez que veamos el "tipo", este dato nos servirá como documentación sobre qué información manejaremos internamente, pero no se traducirá en código explícito (porque el lenguaje no lo provee).
Nota: por eso muchos critican a PHP en general. Al no tener un "tipado fuerte" no lo consideran un lenguaje orientado a objetos "robusto" (al existir menos controles sobre los valores que manejan las variables). Según el autor de PHP, esto es una ventaja del lenguaje -la flexibilidad- y juega en favor de los programadores, no en contra.
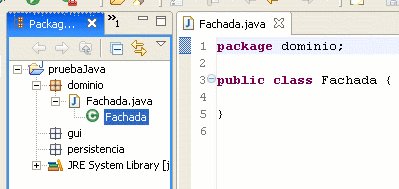
Paso 1) "Nombre del archivo"
Normalmente usamos un nombre seguido de la extensión: prueba.php. En el caso de los objetos, hay muchas opiniones al respecto. La mayoría de los autores sugiere diferenciar un archivo que define una clase de un archivo que usa varias clases predefinidas.
He visto autores que usan la siguiente nomenclatura: class.NombreDeLaClase.php.
En mi caso, yo siempre me sentí más cómodo usando NombreDeLaClase.class.php y así sigo manteniendo la estrategia de no alejarme mucho de Java para contar con un modelo de referencia para poder aprender de él.
La única ventaja que encuentro en la primera opción es que si listamos todos los archivos de un directorio, todos los que empiecen con "class." estarán juntos.
Para seguir el ejemplo, mi ejemplo, usaremos: Persona.class.php
Paso 2) "Definir la clase"
Aquí debemos ceñirnos a la sintaxis del lenguaje de turno al cual queremos convertir desde un diagrama UML. En nuestro caso, es PHP5, por lo cual solo debemos ir hasta el manual, buscar la parte donde hablan de creación de clases y hacer la siguiente conversión mecánica.
 Nota: si usamos Eclipse como IDE para desarrollar, al momento de decirle "crear nuevo archivo php" y colocarle de nombre ".class.php", nos arma un esqueleto más completo de forma totalmente automática ;-)
Nota: si usamos Eclipse como IDE para desarrollar, al momento de decirle "crear nuevo archivo php" y colocarle de nombre ".class.php", nos arma un esqueleto más completo de forma totalmente automática ;-)Paso 3) "Definir los atributos"
Si ya tenemos el esqueleto principal, solo debemos leer uno a uno los atributos del UML y pasarlos a código casi de forma directa:
 Como comentaba, no tenemos que preocuparnos de no disponer de un "tipado fuerte" (como sucede con Java) que nos obligue a escribir en la definición de atributos de que tipo son.
Como comentaba, no tenemos que preocuparnos de no disponer de un "tipado fuerte" (como sucede con Java) que nos obligue a escribir en la definición de atributos de que tipo son.Podemos aplicar algunas "sutilezas" pero que en realidad no aportan mucho valor:
private $nombre="";
Con esta asignación estamos diciendo que el atributo es de tipo String.
En este caso, y para PHP, el tipado en el UML nos aporta información extra para la documentación de nuestro sistema (por lo cual no hay que obviarla a la hora de diseñar, aunque nuestro lenguaje no lo soporte explícitamente).
Paso 4) "Definir los métodos"
Siguiendo el mismo razonamiento que el usado en el caso anterior con los atributos, los métodos deben definir también su visibilidad:
 Paso 5) "Definir un constructor"
Paso 5) "Definir un constructor"Generalmente, aunque esto es flexible, en un diagrama UML que representa una clase no hace falta agregar como método el propio constructor de la clase; en sí, se sobreentiende que constará de uno y no aportaría nada nuevo a la documentación del diseño (de la misma forma que sucedería con los métodos "getter" y "setter", que hablaremos en otro artículo).
Como los atributos son "privados" (no se tiene acceso a los mismos desde fuera de la clase) para poder asignarles valores iniciales en el momento justo de la creación, deberemos crear un método constructor:
 Recibimos los 3 parámetros desde el constructor y luego los asignamos a los atributos de la clase.
Recibimos los 3 parámetros desde el constructor y luego los asignamos a los atributos de la clase.Este método se ejecuta "automáticamente" cuando hacemos un "new" para crear una instancia a partir de la clase (que se ve en el próximo paso).
Paso 6) "Probarlo"
Creamos la clase, usando el constructor, para luego usar un método del objeto.
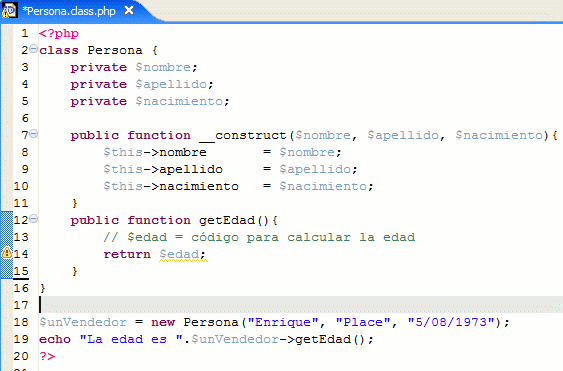
Este ejemplo, en realidad, no imprimirá la edad del "vendedor", puesto que para simplificar el ejemplo y no agregar "ruido" al código (¡si habré visto libros con códigos innecesariamente complejos!), no está implementada la fórmula para calcular la edad a partir de la fecha de nacimiento ingresada (pero creo que la idea general se entiende).
Resumen final
Fuimos viendo paso a paso como se traduce a PHP5 la representación en UML de una clase definida en el contexto de la programación orientada a objetos. Conocimos las 3 zonas que definen una clase (nombre, atributos y métodos), la visibilidad (métodos y atributos), el constructor (para definir un comportamiento al crear el objeto) y finalmente, como probar la clase creada.
¿Dudas o sugerencias? Bienvenidas en los comentarios de este artículo ;-)
Artículo basado en una respuesta que di en Foros del Web
Actualización (27/07/2006): las capturas de pantallas están hechas sobre las siguientes herramientas: la versión "comunitaria" (gratuita) de Poseidon (basado en el proyecto libre ArgoUML) y Eclipse (usando el paquete EasyEclipse for PHP).